谷歌 DeepMind 正在推出Gemini 2.5 Deep Think,该公司表示,这是其最先进的人工智能推理模型,能够通过同时探索和考虑多个想法来回答问题,然后使用这些输出来选择最佳答案。 从周五开始,谷歌每月 250 美元的 Ultrasubscription 的
订阅者将可以在 Gemini 应用程序中访问 Gemini 2.5 Deep Think。
于 2025 月 Google I/O 2.5 上首次亮相,Gemini 2.5 Deep Think 是 Google 首次公开推出可用的多智能体模型。 这些系统会产生多个人工智能代理来并行解决问题,这一过程比单个代理使用更多的计算资源,但往往会产生更好的答案。
谷歌使用 Gemini 2.5 Deep Think 的变体在今年的国际数学奥林匹克竞赛 (IMO) 上获得金牌。
除了 Gemini 2.5 Deep Think,该公司表示,它正在向一组选定的数学家发布其在 IMO 中使用的模型,并学者。 谷歌表示,这种人工智能模型“需要数小时才能推理”,而不是像大多数面向消费者的人工智能模型那样需要几秒钟或几分钟的时间。 该公司希望 IMO 模型能够加强研究工作,并旨在获得有关如何改进学术用例的多智能体系统的反馈。
谷歌指出,Gemini 2.5 Deep Think 模型比它在 I/O 上宣布的模型有了重大改进。 该公司还声称已经开发了“新颖的强化学习技术”,以鼓励Gemini 2.5 Deep Think,以更好地利用其推理路径。
“Deep Think 可以帮助人们解决需要创造力、战略规划和逐步改进的问题,”谷歌在与 TechCrunch 分享的博客帖子中表示。
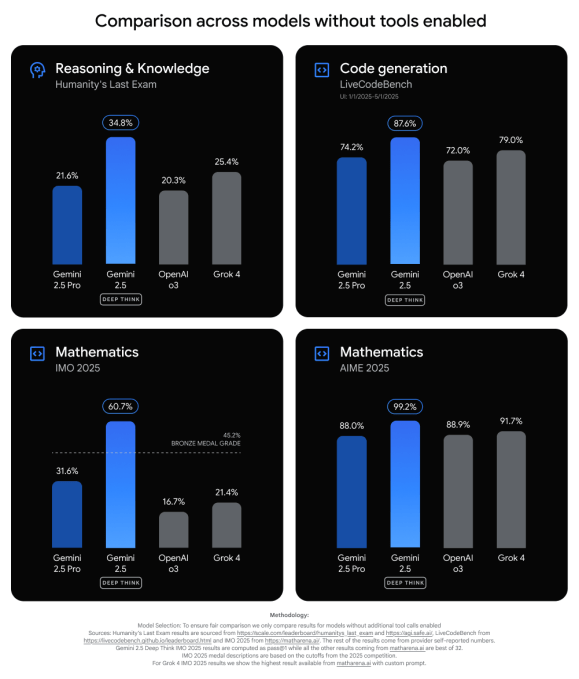
该公司表示,Gemini 2.5 Deep Think 在人类最后一次考试 (HLE) 中取得了最先进的表现,这是一项具有挑战性的测试,衡量人工智能回答数学、人文和科学领域数千个众包问题的能力。 谷歌声称其模型在 HLE(无工具)上得分为 34.8%,而 xAI 的 Grok 4 得分为 25.4%,OpenAI 的 o3 得分为 20.3%。
谷歌还表示,Gemini 2.5 Deep Think 在 LiveCodeBench 6 上的性能优于 OpenAI、xAI 和 Anthropic 的 AI 模型,这是对竞争性编码任务的一项具有挑战性的测试。 谷歌的模型得分为 87.6%,而 Grok 4 得分为 79%,OpenAI 的 o3 得分为 72%。
基准分数图片来源:谷歌
Gemini 2.5 Deep Think 自动与以下工具配合使用代码执行和谷歌搜索,该公司表示它能够产生比传统人工智能模型“更长的响应”。
在谷歌的测试中,与其他人工智能模型相比,该模型产生了更详细、更美观的 Web 开发任务。 该公司声称该模型可以帮助研究人员并“有可能加速发现之路”。

谷歌人工智能制作的艺术场景图片来源:谷歌
似乎几个领先的人工智能实验室正在围绕多智能体方法。
埃隆·马斯克 (Elon Musk) 的 xAI 最近发布了自己的多智能体系统,Grok 4 Heavy,据称该系统能够在多个基准测试中实现行业领先的性能。 OpenAI研究员诺姆·布朗(Noam Brown)在播客上表示,该公司在今年国际数学奥林匹克竞赛上获得金牌时使用的未发布的AI模型也是一个多智能体系统。 同时,Anthropic 的研究代理生成详尽的研究简报,也由多代理提供支持系统。
尽管性能强劲,但多智能体系统的服务成本似乎甚至比传统的 AI 模型还要高。 这意味着科技公司可能会将这些系统限制在他们最昂贵的订阅计划之后,而 xAI 和现在的谷歌已经选择这样做。
谷歌表示,在未来几周内,它计划通过 Gemini API 与一组选定的测试人员共享 Gemini 2.5 Deep Think。 该公司表示,它希望更好地了解开发人员和企业如何使用它的多智能体系统。
